Stochastic Gradient Descent
Most machine learning algorithms and statistical inference techniques operate on the entire dataset. Think of ordinary least squares regression or estimating generalized linear models. The minimization step of these algorithms is either performed in place in the case of OLS or on the global likelihood function in the case of GLM. This property prevents the algorithms from being easily scaled – the statistical models have to be re-estimated every time a new data point arrives. For very large datasets or for datasets with high throughput, this re-estimation step quickly becomes computationally prohibitive. The result is out-of-date models or complex down-sampling logic in the analytical code.
To address this situation in some of the projects we are working on, we’ve been looking at algorithms that operate on streams of data. One such algorithm for estimating GLMs is stochastic gradient descent. SGD allows one to implement “online” statistical learning algorithms in the sense that as new data points arrive, the model parameters are updated in real-time. This has some tremendous advantages – it is highly scalable (memory and computation time) as it operates on one data point at a time, it is real-time and the current optimal model is always available, etc. In order to evaluate the effectiveness of this optimization technique, I put together a demonstration of using SGD to learn an ordinary least squares regression model of a single variable.
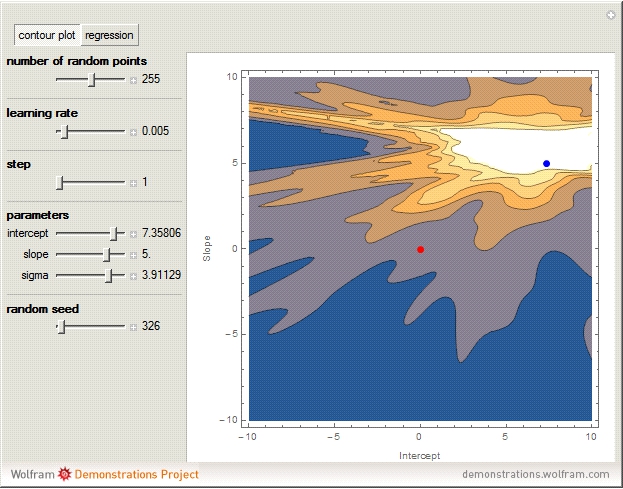
The demonstration shows the global likelihood surface of the regression model. The blue point is the maximum likelihood estimate – equivalent to the least squares solution. The red point is the current values of the SGD algorithm. If you click through to the interactive demonstration, you can observe how the model parameters update as each data point is passed through the SGD algorithm. As more data points are fed to the SGD algorithm, the SGD parameter estimation converges on the maximum likelihood estimation. It is important to note that while we are showing how the algorithm converges in the global likelihood surface, it is in fact not using the surface at all – rather it is operating on the local gradient attributable to each new data point. This is what makes the algorithm scalable and on-line.
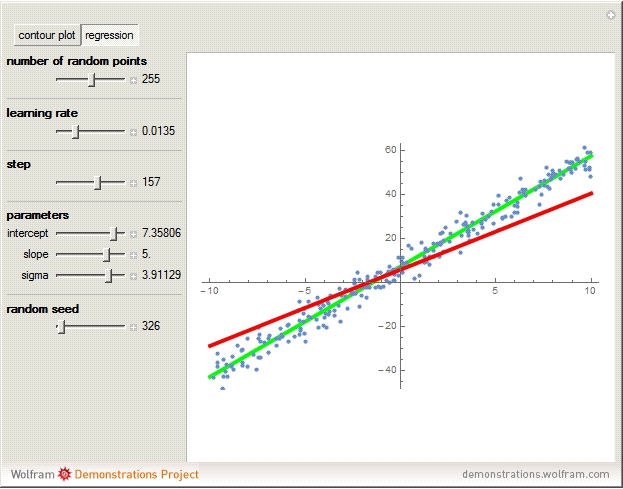
The image on the right shows the SGD regression line and how it approaches the MLE regression line.
There are some potential drawbacks to the SGD algorithm. For one, it may not converge on the optimal model parameters. Second, it is hard to imagine how feature selection could be performed online without a significant ramp up in computational time and memory usage. Third, complex logic needs to be incorporated into the algorithm to decay the impact that old data has on the real-time model and to accentuate the significance of the most recent data. Nevertheless, the overall technique provides significant boosts to efficiency which may outweigh the issues.