Seeing with Deep Learning: Advances and Risks
Self-driving vehicles can read road signs and identify pedestrians. State-of-the-art diagnostic tools can evaluate MRI and CT scans to detect illnesses. Your smartphone can search through your photos and pick out all of the ones with cats. Giving computers the ability to “see”—to take an image or video and accurately recognize its content—has been a goal of researchers since the mid-20th century. However, the widespread adoption of computer vision across so many domains is a recent development, fueled by advances in deep learning and computational power. We are now at the point where, in some tasks, the models we’ve developed to identify the content of images perform beyond human capabilities, and it seems likely that the abilities of these models will continue to grow.
The rise of deep learning-based computer vision models has been accompanied by an associated rise in efforts to fool these models. Known as adversarial attacks, precise alteration can be made to images or scenes that will cause an image classifier to produce the wrong output, and these changes are often indistinguishable to the human eye. As we become reliant on these models for a multitude of tasks, understanding the ways in which models can be made to fail becomes increasingly important; you wouldn’t want to ride in an autonomous vehicle if a small change to a stop sign causes the car to think that stop sign isn’t there.
How to deceive a computer vision model
How hard is it to trick a state-of-the-art-computer vision model? In the GA-CCRi blog entry Generating images and more with Generative Adversarial Networks we saw how Generative Adversarial Networks, or GANs, use neural networks to generate images from scratch that will fool a classification tool. More recently we have explored ways to modify an existing image just enough to make ResNet—one of the top performing neural network model architectures—misclassify one item as another. ResNet has been trained on a large database of images known as ImageNet, which contains images from thousands of different image classes. We performed a series of targeted adversarial attacks where we iteratively adjusted an image of one class to look (to the model) more like an image of another class. How much do we have to modify an image of a cat to make ResNet think it is an umbrella, or an airplane? Are some categories more robust to tampering than others, and can humans even perceive these changes?

In order to cause a neural network to classify an item of one class as an item from another specific class, we must modify the input image in a precise manner. Given that we don’t know what pixels in the image to change and how to change them, we must use a technique to “nudge” an image in the direction of another image category. As it turns out, this method is very similar to the method used to train these networks in the first place.
Normally, through the course of model training, the weights and biases of a neural network are adjusted via backpropagation and gradient descent, with the aim of minimizing a specific loss function. To create an adversarial example, we don’t adjust the weights and biases of the trained model; instead we minimize the loss with respect to the input data. Importantly, we lie to the model and tell it that an image of one class is really of another class, so that the actual effect of minimizing the loss is to make the image appear more like the false class. Successive passes through the network, modifying the image just a tiny bit each time, can push the image past a decision boundary and result in a misclassification, though pushing an image past such a boundary isn’t always possible.

Adversarial susceptibility in ImageNet
Using the ImageNet validation dataset (50,000 images from 1,000 different image categories, with 50 of each category), we attempted to corrupt each image such that it is classified by ResNet as each of the other categories. We then determined, for each image category, how often we could create adversarial examples that fooled the model. Digging deeper, we also investigated what category conversions were easy to make, and which were less likely to occur.
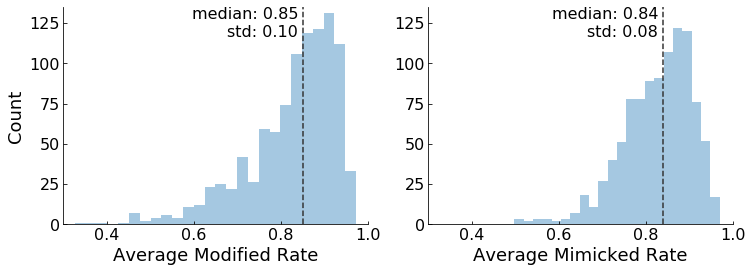
The above figure summarizes our success in creating adversarial examples to fool ResNet. We can think about what it means to fool ResNet in two distinct ways. First, how often were we able to modify an image from one category such that ResNet classified it as a different category? The left histogram shows how easy or hard it was to modify each category. The median modification rate of 85% means that, for half of the categories, we were successful an average of 85% or more of the time in converting an item to a different category. The minimum value was 0.32, indicating that even the category that was most resistant to adversarial tampering—dishrags and dishcloths—could be modified to trick ResNet about a third of the time. On the other extreme, we could create modified images of triceratops capable of tricking ResNet an average of 97.3% percent of the time.


The easiest categories to modify. ImageNet images show a welsh corgi, a polar bear, a triceratops, and a great pyrenees.
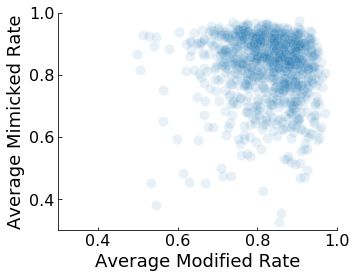
The second way to think about fooling ResNet is by asking how often we were able to mimic specific categories, regardless of the original category of the image. The “Average Mimicked Rate” histogram above shows this result. The median success rate here is similar to that of the first histogram, but, interestingly, the categories that are most easily mimicked are not the same as those that are most easily modified. The scatter plot below shows that there isn’t a clear correlation between these two conditions.


Structure in the data
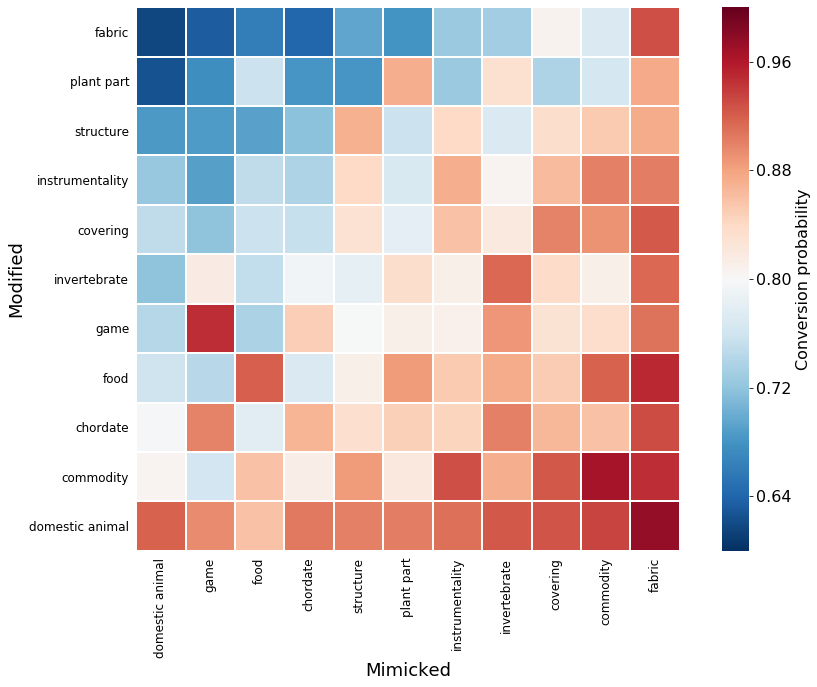
The easiest categories to modify were Welsh corgi, polar bear, triceratops, great pyrenees, and the hardest were dishrag, manhole cover, zebra, monarch butterfly. The easiest categories to mimic were purse, safety pin, jigsaw puzzle, tray, and the hardest were black-and-tan coonhound, chiffonier, Japanese spaniel, and English foxhound. Is there any underlying structure to what types categories are easy to mimic or modify?
To reduce the complexity of trying to look for structure in the results, we can use the hierarchical organization of ImageNet images to group each image into a broader category. Doing so reveals some obvious and interesting differences between image categories. Fabrics were the most difficult to modify, but also the easiest to mimic. Domestic animals were the easiest to modify, but the hardest to mimic. We can speculate as to why this might be: images of fabrics may often contain less structure and be more uniform in appearance, making them unlike other specific categories. Conversely, modifying non-fabric categories by adding noise that removes structure may push them to look like enough like fabric to fool the model.
As this this brief investigation shows, creating adversarial examples that can fool ResNet is not particularly difficult. Perhaps more importantly, we’ve uncovered a bias in the way that the model can be deceived, as some types of images are more susceptible to tampering than others. Knowing a model’s weaknesses is important, and our future work in this domain will attempt to harden our computer version models in order to create more robust and reliable systems.