Get to the Point with Big Spatial Data
In my previous post, I laid out a case for the significance of Big Spatial Data and my surprise that so little is published about it. Now I’ll formally introduce the GeoMesa Project, which seeks to address the challenges faced by developers buried in data with no way to use it.
Introducing GeoMesa
GeoMesa is an open-source suite of tools that enables users to quickly store, index, and query geospatial data at scale. GeoMesa is specifically built to manage large spatio-temporal datasets such as tracks, social media, IoT, or other location data from major mobile applications. Through standards-based interfaces, it can both drive a map user interface or serve data up for analytic queries.
GeoMesa can:
- Store gigabytes to petabytes of spatial data (tens of billions of points or more)
- Serve up tens of millions of points in seconds
- Ingest data faster than 10,000 records per second per node
- Scale horizontally easily (add more servers to add more capacity)
- Support Spark analytics
- Drive a map through GeoServer or other OGC Clients
As an example of Big Spatial Data, this video shows spatially referenced tweets leading up to the Super Bowl in 2015. This visualization is backed by a GeoMesa instance storing billions of tweets.
Why GeoMesa?
Before digging any deeper, let’s first identify some common reasons why you would turn to GeoMesa:
- You have Big Spatial Data sets and you are reaching performance limitations of relational database systems. Perhaps you are looking at sharding strategies and wondering if now is the time to look for a new solution.
- You have very high velocity data and need high read and write speeds.
- Your analytics operate in the cloud. Perhaps your analytic runs in Spark and you want to enable spatial analytics.
- You are looking for a supported open-source alternative to expensive proprietary solutions.
- You are looking for a Platform as a Service (PaaS) Database where you can store Big Spatial Data.
- Filter data using the rich Common Query Language defined by the OGC.
GeoMesa History
As I discussed before, spatio-temporal data have tremendous value, but storing large volumes of these data in such a way that they can be efficiently queried is complex. GA-CCRi originally developed GeoMesa to serve as a platform for analytic and visualization tools supporting a spatial threat prediction analytic used by the U.S. Army to forecast the location of asymmetric warfare events in Afghanistan. After using the tool to support several of our own unrelated analytics, we recognized the value of the system to the community and decided to open-source the technology.
Today, GeoMesa integrates with Apache Accumulo, Apache HBase, and Google Cloud Bigtable.
Standards
From the beginning, our goal was to build to Open Geospatial Consortium standards. Specifically, GeoMesa implements the GeoTools Interfaces, and through GeoServer it supports:
- Web Feature Service (WFS)
- Web Mapping Service (WMS)
- Web Processing Service (WPS)
- Web Coverage Service (WCS)
As you likely know, these are the prevalent standards used today for accessing spatial data; so integration with new or existing applications is very easy. In fact, if an application already uses GeoServer, the integration is simply a matter of adding a new datastore to GeoServer and updating the application’s configuration.
How Does GeoMesa Work?
Like many other foundational technologies, the heart of GeoMesa is relatively simple. To understand it, you probably need to know a few basic principles. To make this as painless as possible, I’ve labeled the next few headings so you can skip things you already know about.
Key-Value Datastores
Every record in a key-value database is stored and retrieved using a key. The key is a unique identifier for the record. Accumulo, HBase, and Google Cloud Bigtable sort the keys and store them across any number of nodes (servers). So, the magic of key-value databases is how you generate the keys. Unlike relational databases, where the keys are frequently sequential integers, key value stores usually use the key to represent a feature by which the data are frequently queried. So, you could imagine a database of customer orders being indexed by the order number. Then, when a client queries by order number, the database goes directly to that key and returns the value (i.e., the record). While the key structures of Accumulo, HBase, and Cloud Bigtable are more complex than I’ve described here, the foundational principle of GeoMesa can be explained in terms of keys and values. To store spatio-temporal data, we need to create a key that represents the time/space location of the record.
Space Filling Curves
Rather than bore you with mathematical definitions of space filling curves, I’ll start by showing you one:

The red line is a space filling curve, or to be more specific, it is a Z-Curve. This line visits each cell exactly once, establishing a unique ordering of cells. Space filling curves can also work at multiple resolutions, as shown here:
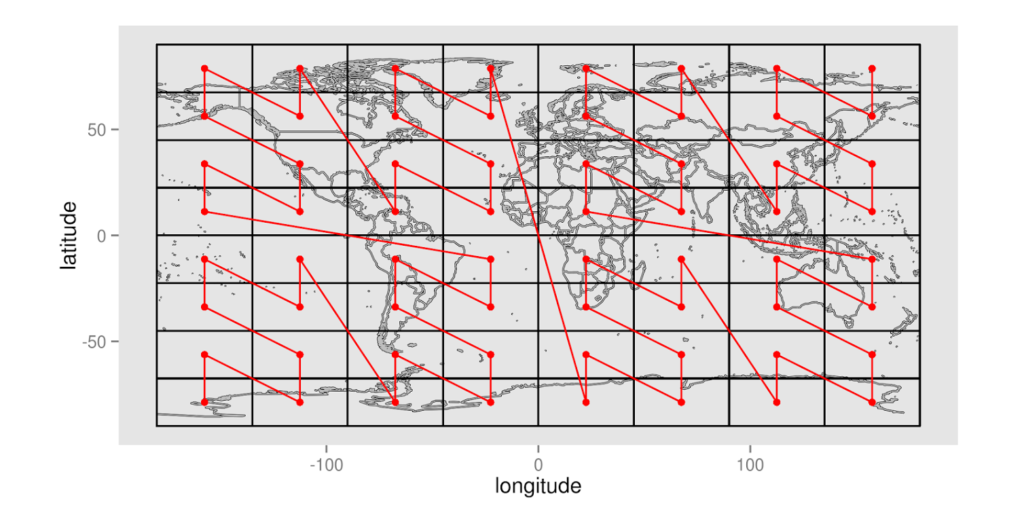
Each point in this curve can be assigned a sequential value. By doing so, we’ve converted the latitude and longitude pair into a single integer. This is quite handy if you are trying to represent two-dimensional data in a one-dimensional key, as is the case with a key-value datastore. Even more significantly, these space filling curves can be adapted for n-dimensions. Thus, n-dimensions of data can be linearized into a single dimension.
GeoMesa’s Index
So, you’ve probably put two and two together at this point; but the basic principle of GeoMesa’s Index is to take the three dimensions of longitude, latitude, and time, then create a three-dimensional space filling curve, use the values of the points along this curve as the key, and voila! Now we can store the record in a key-value store with a key that represents all three dimensions of data we query by most frequently.
I know I’ve left at least a few of you hungry for more detail. For you, I am writing a few more posts where I will dive into the specifics. These posts will be on GA-CCRi’s blog, indexed by the GeoMesa Category. Please stay tuned. Until then, here is the real structure of GeoMesa’s Index in Accumulo:
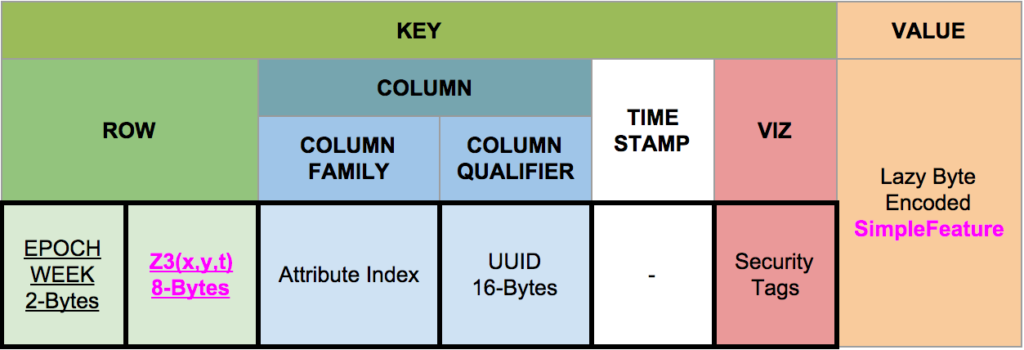
As you can see, the actual key structure is more complex than a simple key-value pair. Nevertheless, you will see (in bright pink) the Z3 encoding in the Key Section and the Simple Feature (your spatial record) in the Value Section. The structure of the key can be adjusted depending on the data, but this is the default.
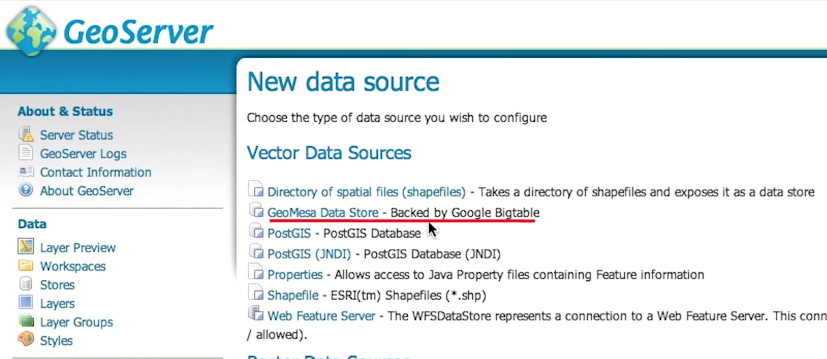
GeoServer Integration
GeoMesa has a plugin to GeoServer which allows developers to add GeoMesa Datastores into GeoServer. Everything else is the same. GeoServer will expose WMS, WFS, WPS, and WCS, to which your maps or analytics can connect . If you wish to implement computationally intensive analytics on the spatial data, they can be implemented as Web Processing Services (WPS) and registered in GeoServer for easy integration into your application.
If you are already using GeoServer, then switching to GeoMesa can be a matter of changing a few configurations – your application will likely not require any code changes.
Community and Support
While we at GA-CCRi are avid consumers of open-source software, GeoMesa is the first system we have had the chance to offer back to the community. In doing so, we have learned many important lessons, the most important being to release the software into an existing community. We reached out to the Eclipse Foundation and now GeoMesa is now an official project in Eclipse’s LocationTech Working Group. Joining LocationTech has been a wonderful decision for a multitude of reasons, which I will detail in a future post.
As with any open-source project, community and contributors are essential. If you want to get involved, feel free to start by joining GeoMesa’s mailing list on the GeoMesa.org website.
If you are looking for support, a proof of concept, or to get up and running quickly with GeoMesa, GA-CCRi offers a range of services around the GeoMesa system. For more information, please fill out our information request form. GA-CCRi is partnered with Boundless to provide support for the OpenGeo Suite running on GeoMesa.
To keep up-to-date with the latest work going on at GA-CCRi, follow us on Twitter at @ccr_inc.