Cloud Computing With Spark: Using All Your executors
Sometimes Data Scientists find themselves with a map-reduce cloud architecture and computation that needs to be done on a large scale, but the data isn’t actually cloud scale. One great way to get the cloud working for you is a framework like Apache Spark, which can make it simple to cloud-enable your computation. However, modern map-reduce style clouds are built assuming really big data where its best to execute code right on the cluster nodes where the data reside. Having a small amount of input data (just a couple hundred MB of objects at most) but a large search/compute space caused us some trouble and this is how we resolved the issue to get all the compute power we could out of our cloud.
The problem: A method called Triangulate-All was running slowly on our development cloud even after I asked Yarn (Hadoop MapReduce 2.0) for 40 executors, and got them… to the tune of 177minutes! This is definitely not your usual count-stuff and reduce over some keys type Spark job. We needed to compute several things across a spatial grid and touch (accumulate) values in basically all the grid cells. Investigations into the slowness revealed that the data (stored in RDDs) were only spread across two partitions. This severely limited Sparks execution job planning.
If you ever use SparkContext.textFile() to read some data (and surely you started here, because that is what is provided in the Spark documentation — “Programming Guide”), beware the second parameter which is not required. It defaults to “defaultMinPartitions” (2) for the RDD it creates and all RDDs derived from said source inherit this tiny number of partitions. Executors without RDD blocks (obviously) can’t perform calculations… they don’t have any data!
For this project we have taken approximately four steps to “force” Spark to spread our relatively small amount of data more widely.
1) Detect the number of executors from the SparkConf at startup time (since we may request any number from Yarn, and may not get them all anyway):
[code language=”scala”]val numExecutors = iniSparkConf.getInt("spark.executor.instances",2)[/code]2) Force SparkContext.textFile() to use this as the number of partitions to create
[code language=”scala”]val sectorData = sc.textFile(sectorFile, numExecutors)[/code]3) Forcibly repartition using this number before persisting to ensure data spreading. Ok, this might be overkill, but its not much overhead and seems to have helped in our testing. Without the extra repartition we tended to still get some nodes with zero RDD blocks.
[code language=”scala”]{???}.repartition(numExecutors).persist(…)[/code]4) Set the StorageLevel to include replication so more unique executors get a copy, even if it is redundant.
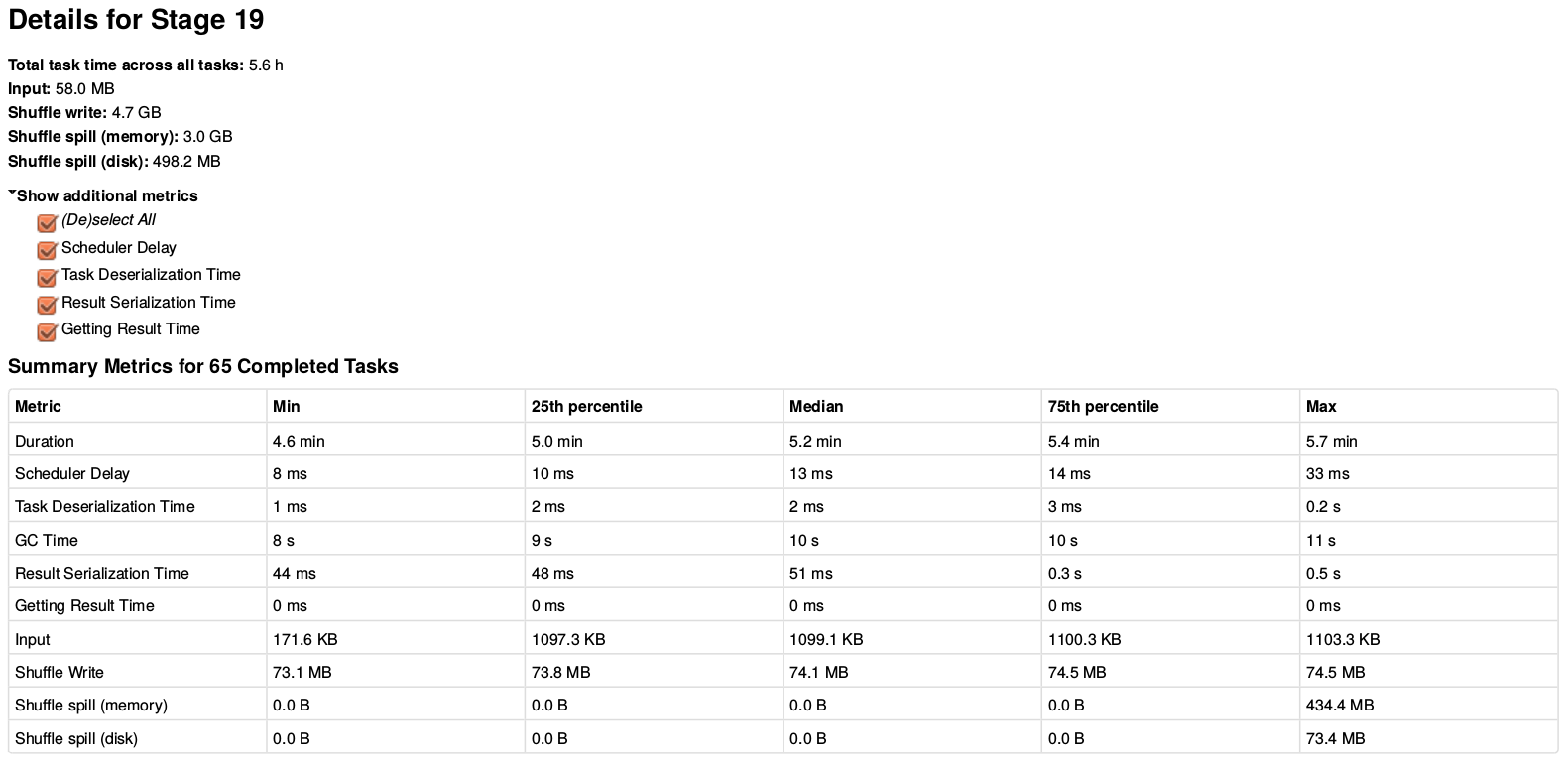
[code language=”scala”]{???}.repartition(numExecutors).persist(StorageLevel.MEMORY_AND_DISK_2)[/code]Now that all the executors get some data the jobs/stages are using all the executors. In this run I had 40 executors on our development cloud (plus the driver which is my desktop machine). During the longest stage of this Triangulate-All job we got 5.6 hours of compute time done in about 6 minutes. Check out the table below if you want all the gory timing and memory details.
In the end the 177minute job got done in 12.1 minutes, nearly a 15x improvement.