Ketos: neural networks for document retrieval
Overview
GA-CCRi has developed a document retrieval system named Ketos which builds upon recent breakthroughs in language understanding via neural networks. Most currently available text retrieval software lacks semantic representation for text and essentially matches the various facets of a query in isolation, while our method treats a document as a coherent whole and delivers thematically relevant results. Ketos has been deployed as a plugin to Apache Solr for smooth integration with existing infrastructure. We briefly summarize our approach and results below.
Document models
Modeling language with neural networks is a highly active and rapidly maturing field. Language agnostic models can now be efficiently trained on raw text containing billions of words, and they achieve state of the art performance on many natural language processing tasks such as tagging parts of speech, semantic role labeling, and sentiment analysis. Most of the word-based models depend on the distributional hypothesis: words have similar meanings if and only if they occur in similar contexts. Starting from this simple yet profound insight, word embedding models now show excellent performance in synonym clustering and analogy completion [1].
There are several neural models that attempt to represent longer lexical items e.g. phrases, sentences, paragraphs, or documents. Recursive neural networks are useful for compositional representation of sentences, but it is not clear how to adapt them to longer blocks of text [2]. Convolutional style networks [3] can be applied to text items of arbitrary size, but for longer documents they are still outperformed by the classical term frequency inverse document frequency (TF-IDF) statistic. It seems that representing long documents is a fundamentally coarser problem than modeling words or phrases. Therefore, it is natural to examine the weaknesses of TF-IDF and try to improve it by incorporating a learning algorithm.
TF-IDF
The goal of TF-IDF is to rank the words in a document by their relevance and importance to the overall theme and meaning of the text. Intuitively, we are interested in words that have high incidence within a given document but do not commonly appear across all the other documents in the corpus. Although TF-IDF is widely used in document retrieval systems and performs quite well, it has several shortcomings.
- No semantic representation of words: TF-IDF cannot identify synonyms, which makes it prone to miss similar documents that simply use different words to describe the same concept. For example, the phrases “the lion walks” and “a predator prowls” are semantically similar but have zero TF-IDF similarity.
- Noise introduced by common words: Since common words will have small but non-zero TF-IDF values, it is possible for two documents to be identified as similar based on superficial syntactic overlap.
- Unwieldy size of sparse vectors: If the vocabulary is very large, the TF-IDF vectors can be impractical for storage and computation.
Ketos model
GA-CCRi’s Ketos system uses a neural network document embedding algorithm that leverages TF-IDF information while directly addressing the above-mentioned issues. We make use of a global version of the TF-IDF statistic which we refer to as information content. The information content of a word is equal to its inverse document frequency multiplied by the log of the total number of times it appears in the corpus. Intuitively, this statistic identifies those words that are relatively common in the corpus but are distinctive in that they only appear in a relatively small number of documents. The table below gives examples of words with high/low information content as computed from the Reuters-21578 dataset of news articles.
| Words with high information content | Words with low information content |
| OPEC, OECD, sugar, Taiwan, Poehl | of, said, the, and, to, a, in |
The information content distribution of the words which appear in at least ten documents is given below. The sharp peak in the figure corresponds to the clustering of words at the trade-off point between the competing objectives of maximizing word frequency and minimizing document frequency.
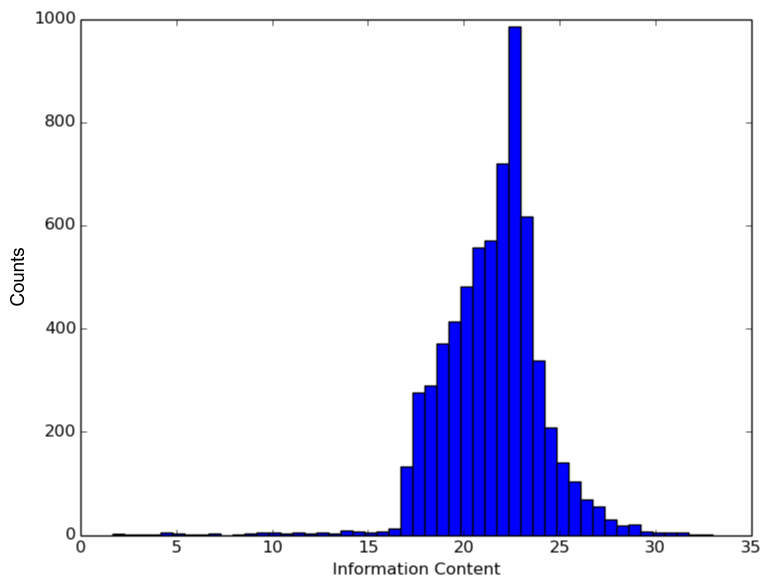
We also define the context signature of a word w to be the sparse vector whose non-zero entries correspond to the information content of words appearing directly before or after w in some document. For example, the table below lists the top twenty highest information content words in the context signatures of France and Germany.
| Context sample for France | Context sample for Germany |
| OECD, sugar, Venezuela, Mobil, Yugoslavia, Brazil, Spain, Carbide, minus, southern, war, Italy, backed, pacts, posted, great, western, northern, intervened, dealers | Bolivia, Lawson, Taiwan, Stoltenberg, Venezuela, Jacobs, Siemens, consumers, Portugal, Italy, backed, German, overseas, W., imported, unions, analysts, south, Belgium, East |
These context signatures are not very informative or useful by themselves, but a neural model can learn the “limit” of all the implicit relations contained therein and produce a high-quality semantic representation. We use the following steps to improve on TF-IDF document vectors:
- Automatically generate stopwords: We remove any words from the vocabulary that do not meet a certain information content threshold. This step removes those words that are either too common or too rare, which would add noise to the TF-IDF signal, and reduces the number of words to be trained.
- Neural word embedding model: We learn word embeddings using a neural network with the context signature of each word as a target vector. This architecture provides a stable information signal and facilitates online training since we simply update the vocabulary and context signatures as new documents are ingested.
- Compact TF-IDF weighted document vectors: After training the word embeddings, we pass the sparse TF-IDF vectors through the neural network to produce a compact, high-quality vectors which have the combined advantages of TF-IDF weighting and semantic representation. In the simplest case, this computation is equivalent to taking a TF-IDF weighted average of the word embeddings for the set of words in a document.
The Ketos model achieves better precision and recall performance compared to off-the-shelf TF-IDF-based document retrieval systems. It also outperforms Doc2vec, which is an implementation of the neural embedding model described in [3]. Below we have a plot of interpolated precision and recall for all three models, where the query documents were sampled from the 25 most common tags in the Reuters dataset.

Ketos Solr plugin
GA-CCRi has implemented Ketos as a plugin to Apache Solr, in order to replace the built-in “MoreLikeThis” functionality. For example, the table below displays the top five titles returned by Solr MoreLikeThis and the Ketos plugin in response to a query document with the title “GROUNDED BRITISH BAUXITE VESSEL REFLOATED IN ORINOCO.”
| Solr MoreLikeThis | Ketos Plugin |
| BRITISH BAUXITE VESSEL GROUNDED IN ORINOCO RIVER | BRITISH BAUXITE VESSEL GROUNDED IN ORINOCO RIVER |
| LIBERIAN SHIP GROUNDED IN SUEZ CANAL REFLOATED | TURKISH SHIP HEADED FOR FLORIDA AFTER EXPLOSION |
| SURALCO BAUXITE REFINERY REOPENED | TUGS TO ATTEMPT REFLOATING KOREAN BULK CARRIER |
| UK SUGAR FACTORY CLOSES DUE TO SHORTAGE OF BEET | LIBERIAN SHIP GROUNDED IN SUEZ CANAL REFLOATED |
| MOSCOW SUPPORTS FREE GULF NAVIGATION, ENVOY SAYS | INDIA REPORTED BUYING TWO WHITE SUGAR CARGOES |
Note that both search algorithms find the closely-related article about when the ship first ran aground, but Solr MoreLikeThis seems to focus on isolated facets of the query document, while the Ketos plugin synthesizes the details into a coherent account and retrieves similar thematic content.
Metadata embeddings
The semantic representation provided by a document embedding model also has several additional benefits. For example, since metadata items and user interactions can be viewed as sequences of vectors, we can model them using any algorithm that embeds sequential data. By embedding these artifacts in word/document space, we enable multi-faceted and semantically aware queries such as “documents with similar authors and locations” or “users with similar interests.” To give a concrete example, the plot below is a two-dimensional t-SNE [4] representation of the learned embeddings for keywords in the Reuters dataset.
The size of the circles correlates with the number of documents tagged with the given keyword. The colors correspond to a clustering in 100-dimensional embedding space. We can clearly see the topical groupings corresponding to economic issues, metals, fuels, and food commodities. Even though some of these keywords do not appear within the text of any of the documents, we can still represent their semantic content in a useful way.
References
[1] T. Mikolov, K. Chen, G. Corrado, and J. Dean . “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).[2] R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts. “Recursive
deep models for semantic compositionality over a sentiment treebank.” In EMNLP (2013).[3] Q. V. Le and T. Mikolov. “Distributed Representations of Sentences and Documents.” arXiv preprint arXiv:1405.4053 (2014).[4] L.J.P. van der Maaten and G.E. Hinton. “Visualizing High-Dimensional Data Using t-SNE”. Journal of Machine Learning Research 9: 2579–2605 (2008).